Categories Photography Silent Sunday June 9 2024 Post author By Shelley Powers Post date June 9, 2024 Tags pride, silentsunday
Categories Diversity Photography Silent Sunday June 2 2024 Post author By Shelley Powers Post date June 2, 2024 Pride Parade 2005 Tags pride, silentsunday
Categories Photography Silent Sunday May 26 2024 Post author By Shelley Powers Post date May 26, 2024 Jefferson Barracks National Cemetery in St. Louis Tags memorialday, silentsunday
Categories Photography Silent Sunday May 19 2024 Post author By Shelley Powers Post date May 19, 2024 Hordes of tourists watching hordes of sea lion at Pier 39 in San Francisco Tags silentsunday
Categories Photography Silent Sunday May 12 2024 Post author By Shelley Powers Post date May 12, 2024 Bright yellow flower after rain Tags silentsunday
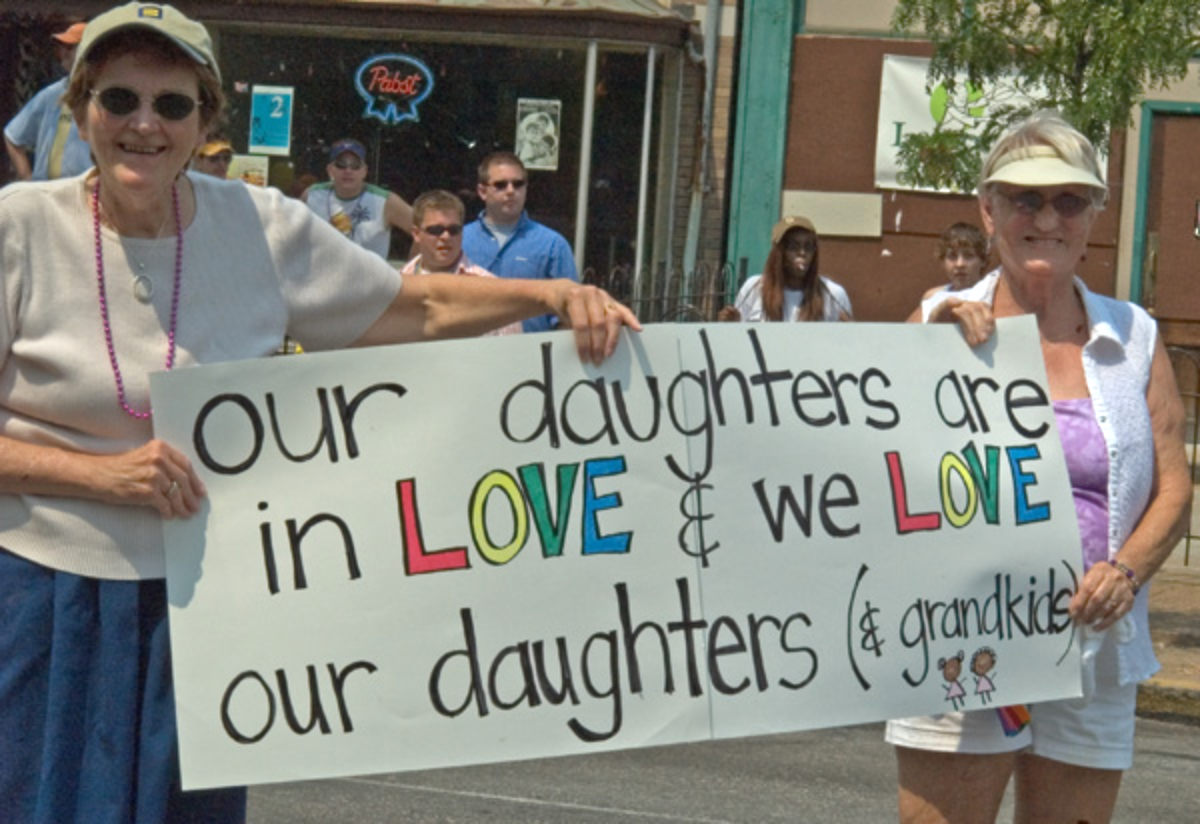
 Burningbird
Burningbird



