
We have so many real problems and serious dangers associated with a Trump administration partnered with a compliant Congress. We don’t need to generate fictional dangers based on happenstance and conspiracy. Yonatan Younger wrote a compelling and well-sourced text laying out the various arguments that what Trump’s administration is doing is equivalent to performing a […]
Categories
Trump Transition Leaves Chaos in Wake

Former EPA staffers said Wednesday the restrictions imposed under Trump far exceed the practices of past administrations.Update: The AP has news that the EPA must submit all studies and data to review by political appointees. Former EPA staffers said Wednesday the restrictions imposed under Trump far exceed the practices of past administrations. Earlier: It’s not […]

Trump has signed executive orders reversing President Obama’s administration’s decisions on both the Keystone and the Dakota pipelines. The Dakota pipeline is currently under review by the Army Corps of Engineers. The Corps is preparing an Environmental Impact Statement on the route and alternatives. Trump can’t just upend this effort with an executive order—not without Earth […]
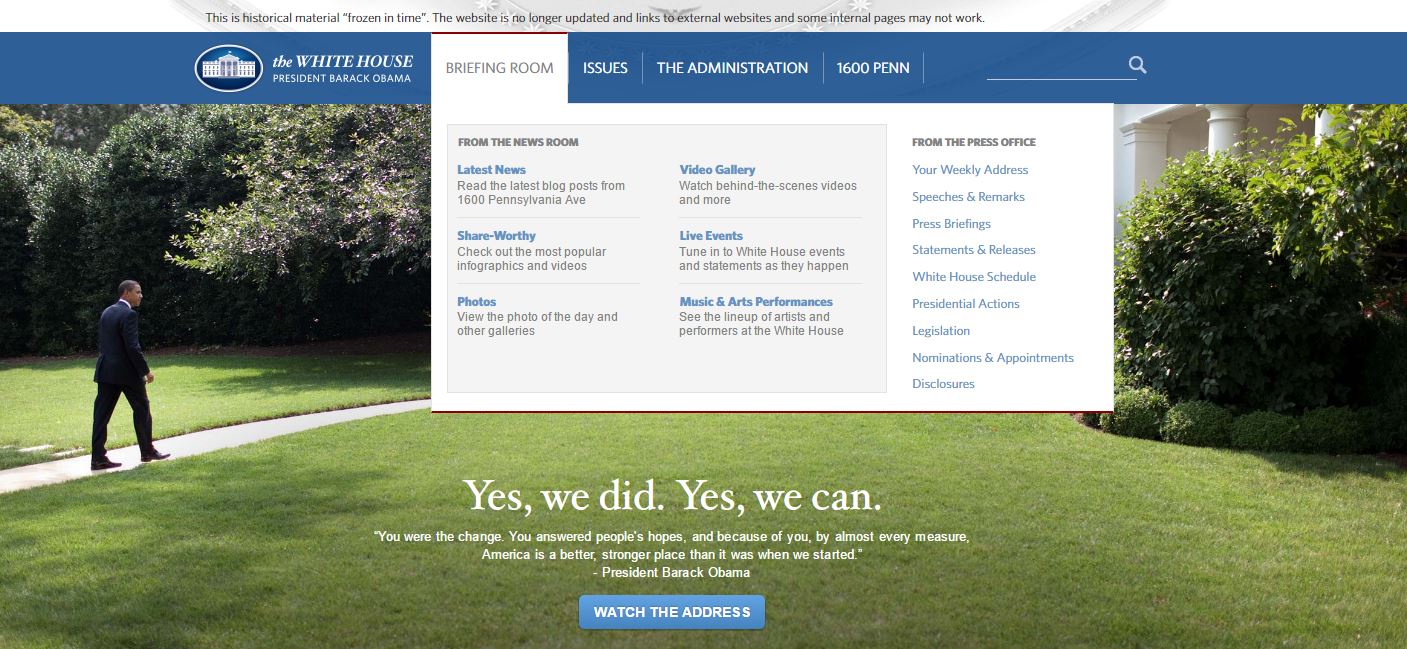
Several people have tweeted about how the climate change page is no longer posted to the whitehouse.gov web site. What they’re not aware of is that this change was planned starting last October. First of all, whitehouse.gov reflects whoever is the occupant of the White House. Unlike the EPA or Department of Labor web sites, […]

I don’t join “movements”. I’ve seen them co-opted too many times. I saw this with Blogher, which was supposed to be a movement to give attention and voice to women writers. But three people turned it into a profit-making venture and ruined everything. We also saw this with Occupy and Black Lives Matter. Now we’re seeing […]